- 发表于
2022-06-29 乐鑫面试 记录
- Authors
- 作者
- Masachi Zhang
- @MasachiZhang


1. redux 三大原则
- 整个应用只有一个 store
- store 中的数据无法被直接修改
- store 只能通过 reducer 纯函数来修改
2. React 为什么不是 class 而是 className
- class 是关键字
- js 会使用 dom.className 获取样式名,跟 js 保持一致
3. React setState replaceState
- setState 是修改其中的部分状态,相当于 Object.assign,只是覆盖,不会减少原来的状态;
- replaceState 是完全替换原来的状态,相当于赋值,将原来的 state 替换为另一个对象,如果新状态属性减少,那么 state 中就没有这个状态了。
4. Flex 布局 (Flex Order)
控制子组件在 flex 布局中的先后顺序,默认为 0,可以为负,值越大布局越靠后,当值相等时,就根据写的先后顺序进行显示
5. Java synchronized
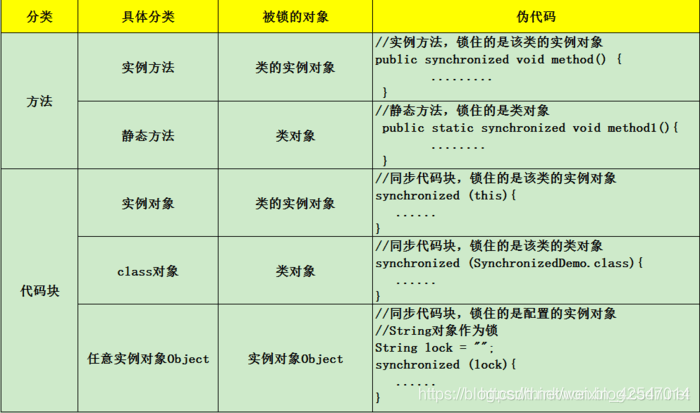
- 修饰实例方法:作用于当前对象实例加锁,进入同步代码前要获得 当前对象实例的锁
- 修饰静态方法: 也就是给当前类加锁,会作用于类的所有对象实例 ,进入同步代码前要获得 当前 class 的锁。因为静态成员不属于任何一个实例对象,是类成员( static 表明这是该类的一个静态资源,不管 new 了多少个对象,只有一份)。所以,如果一个线程 A 调用一个实例对象的非静态 synchronized 方法,而线程 B 需要调用这个实例对象所属类的静态 synchronized 方法,是允许的,不会发生互斥现象,因为访问静态 synchronized 方法占用的锁是当前类的锁,而访问非静态 synchronized 方法占用的锁是当前实例对象锁。
- 指定加锁对象,对给定对象/类加锁。synchronized(this|object) 表示进入同步代码库前要获得给定对象的锁。synchronized(类.class) 表示进入同步代码前要获得 当前 class 的锁
总结:
- synchronized 关键字加到 static 静态方法和 synchronized(class) 代码块上都是是给 Class 类上锁。
- synchronized 关键字加到实例方法上是给对象实例上锁。
- 尽量不要使用 synchronized(String a) 因为 JVM 中,字符串常量池具有缓存功能
synchronized 本身具备的特性
可重入性:synchronized 锁对象的时候有个计数器,他会记录下线程获取锁的次数,在执行完对应的代码块之后,计数器就会-1,直到计数器清零,就释放锁了。可以避免一些死锁的情况。
不可中断性: 不可中断就是指,一个线程获取锁之后,另外一个线程处于阻塞或者等待状态,前一个不释放,后一个也一直会阻塞或者等待,不可以被中断。值得一提的是,Lock 的 tryLock 方法是可以被中断的。
6. Java volatile
volatile 是 Java 虚拟机提供的轻量级的同步机制,它有3个特性:
- 保证可见性
- 不保证原子性
- 禁止指令重排
7. Java super 方法
当子类与父类有同名的属性时,可以通过 super。属性的方式调用父类中生命的属性。
当子类重写父类的方法后,在子类中若想调用父类中被重写的方法时,需用 super.的方法
super 修饰构造器,通过在子类中使用 super 列表参数的形式调用父类中制定的构造器
- 在构造器内部,super(参数列表)必须声明在首行
- 在构造器内部,this(参数列表)或 super(参数列表)只能出现一个
- 当构造器中不显示的调用 this(参数列表)或 super(参数列表)默认调用父类中的空参构造器
8. Java HashMap 和 HashTable 的区别
线程是否安全 HashMap 是非线程安全的,Hashtable 是线程安全的,因为 Hashtable 内部的方法基本都经过 synchronized 修饰。(如果你要保证线程安全的话就使用 ConcurrentHashMap );
效率 因为线程安全的问题,HashMap 要比 Hashtable 效率高一点。另外,Hashtable 基本被淘汰,不要在代码中使用它;
对 Null key 和 Null value 的支持 HashMap 可以存储 null 的 key 和 value,但 null 作为键只能有一个,null 作为值可以有多个;Hashtable 不允许有 null 键和 null 值,否则会抛出 NullPointerException。
初始容量大小和每次扩充容量大小的不同 :
创建时如果不指定容量初始值,Hashtable 默认的初始大小为 11,之后每次扩充,容量变为原来的 2n+1。HashMap 默认的初始化大小为 16。之后每次扩充,容量变为原来的 2 倍。
创建时如果给定了容量初始值,那么 Hashtable 会直接使用你给定的大小,而 HashMap 会将其扩充为 2 的幂次方大小(HashMap 中的 tableSizeFor()方法保证,下面给出了源代码)。也就是说 HashMap 总是使用 2 的幂作为哈希表的大小,后面会介绍到为什么是 2 的幂次方。
底层数据结构 JDK1.8 以后的 HashMap 在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为 8)(将链表转换成红黑树前会判断,如果当前数组的长度小于 64,那么会选择先进行数组扩容,而不是转换为红黑树)时,将链表转化为红黑树,以减少搜索时间。Hashtable 没有这样的机制。
判断包含的方法 Hashtable 有 contains 的方法。HashMap 是 Hashtable 的轻量级实现,HashMap 把 Hashtable 的 contains 方法去掉了,改成 containsvalue 和 containsKey。因为 contains 方法容易让人引起误解。
9. Java TCP UDP 开发
UDP
UDP 协议是一种不可靠的网络协议,它在通信的两端各建立一个 Socket 对象,但是这两个 Socket 只是发送,接收数据的对象,因此对于基于 UDP 协议的通信双方而言,没有所谓的客户端和服务器的概念。
Java 提供了 DatagramSocket 类作为基于 UDP 协议的 Socket
UDP 发送数据步骤:
1.创建发送端的 Socket 对象 (DatagramSocket) 2.创建数据,并把数据打包 调用 DatagramSocket 对象的方法发送数据 3.关闭发送端 UDP 接收数据步骤: 1.创建接收端的 Socket 对象 (DatagramSocket) 2.创建一个数据包,用于接收数据 3.调用 DatagramSocket 对象的方法接收数据 4.解析数据包,并把数据在控制台显示 5.关闭接收端
TCP
Java 对基于 TCP 协议的的网络提供了良好的封装,使用 Socket 对象来代表两端的通信端口,并通过 Socket 产生 IO 流来进行网络通信。 Java 为客户端提供了 Socket 类,为服务器端提供了 ServerSocket